Nextflow Advanced
Use the scalability of AWS Batch to run Nextflow workflows. This is ideal for large workloads and larger data-sets.
Watch a video on how to provision a Nextflow-Advanced product
Parameters
Parameter |
Details |
|---|---|
Product Name |
Provide a name to help you easily identify this instance of the product. Only alphanumeric characters, dots, hyphens and underscores are allowed. Spaces and special characters are not allowed. Eg: MedicalResearch |
Study Selection |
Expand the section to select studies to mount to your workspace.Select one or more studies to mount to your workspace from the dropdown list(Maximum of 2) |
Nextflow Configuration |
|
PipelineName |
Search and select the pipeline git repository URL. If not found please enter the custom pipeline URL. The repo should contain the nextflow.config file which specifies the name of the docker container image. Eg: https://github.com/seqeralabs/nextflow-tutorial.git |
PipelineContainer |
Public Docker container image of the pipeline to be executed. If you are using a custom pipeline, ensure that the custom container image is publicly available on Docker Hub Eg: nextflow/rnaseq-nf:latest |
InputDataLocation |
An S3 bucket which holds input data for the Nextflow pipeline. The bucket name must respect the S3 bucket naming conventions (can contain lowercase letters, numbers, periods and hyphens). |
InputDataPattern |
The pattern to match samples to be processed as inputs to the pipeline. Eg: data/ggal/*_{1,2}.fq. It can also point to a csv or tsv file that contains details of the files to be processed. |
OutputDataLocation |
The full path on the local disk where outputs of the pipeline should be stored. The default path above will enable you to view the outputs via the browser. The path should be accessible to the user ec2-user. Alternately, provide an S3 bucket for storing analysis results. The bucket name must respect the S3 bucket naming conventions (can contain lowercase letters, numbers, periods and hyphens). |
Head Node Configuration |
|
InstanceType |
Head Node EC2 instance type. Eg: t2.micro |
HeadNodeEBSVolumeSize |
The initial size of the volume (in GBs) Head Node EBS will use for storage. Eg: 16 |
KeyPair |
Name of an existing EC2 KeyPair to enable SSH access to the Head Node. If no key pairs exist, please create one from the button next to the dropdown. Please contact your Administrator if you are unable to create one. |
AllowedSSHLocation |
The IP address range that can be used to SSH to the Head Node. For the security of your instance, we recommend you allow connections only from your own location. You can find your IP using https://whatismyipaddress.com/ Eg: 0.0.0.0/0 |
Batch Configuration |
|
VPCId |
Choose VPC Id in the drop-down list. |
WorkerNodeSubnetId |
Choose Subnet Id in the drop-down list. Subnet you want your Batch Worker Node to launch in. We recommend public subnets. |
ComputeEnvMinvCpus |
The minimum number of CPUs to be kept in running state for the Batch Worker Nodes. If you give a non-zero value, some worker nodes may stay in running state always and you may incur higher cost. Eg: 0 |
ComputeEnvMaxvCpus |
The maximum number of CPUs for the default Batch Compute Environment. Eg: 100 |
SpotBidPercentage |
The maximum percentage of On-Demand pricing you want to pay for Spot resources. You will always pay the lowest Spot market price and never more than your maximum percentage. Eg: 100 |
WorkerNodeInstanceType |
Specify the instance types to be used to carry out the computation. You can specify one or more family or instance type. The option ‘optimal’ chooses the best fit of M4, C4, and R4 instance types available in the region. Eg: Optimal |
WorkerNodeEBSVolumeSize |
The initial size of the volume (in GBs) Worker Node EBS will use for storage. Eg: 100 |
Steps to launch
Click on the project on the “My Projects” page.
Navigate to the available products tab.
Click the “Launch Now” button on the “Nextflow-Advanced” product card. A product order form will open. Fill the details in the form .
Note
- PipelineName
You can see the drop down option which is on the right side of the PipelineName field.
You can search the pipeline. If you type the correct pipeline you can see the info (ie.,”i”) icon which is at the right side of the field. If you click the info icon it will be routed to the seqerlabs/nextflow-tutorial repository. If you type the wrong characters it will throw an error message accordingly.
- InputDataLocation
You can see the filter options like All/Studies/Shared/ProjectStorage/Study in the Second part of the InputDataLocation field.
You can see the default option like “All” in the filter.
You can see the product names with realted paths when you search in the InputDataLocation field. You need to select the S3 bucket name or project storage buckets from the available list.
If you type the invalid characters it will throw an error message accordingly.
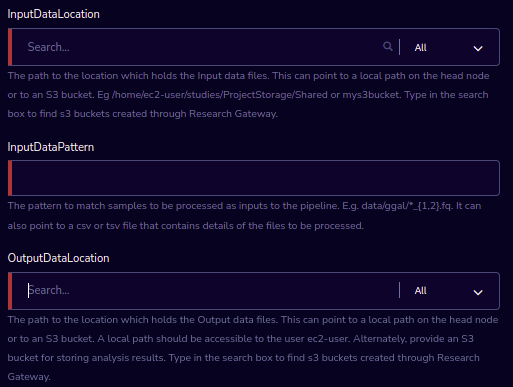
- InputDataPattern
This is a plain edit field.
The pattern to match samples to be processed as inputs to the pipeline (Eg: /data/ggal/*_{1,2}.fq). It can also point to a csv or tsv file that contains details of the files to be processed.
- OutputDataLocation
Defaultly you can see the output path in the field.
You can see the product names with realted paths when you search in the OutputDataLocation field.
You can see the filter options like All/Studies/Shared/ProjectStorage/Study.
You can see the default option like “All” in the filter.
If you type the invaliad characters it will throw an error message accordingly.
Click on the “Launch Now” button. You will see a “Nextflow-Advanced” being created. In a few minutes, that product should appear in the “Active” state.
Estimated time to provision - 10 minutes
Steps to connect
Click on the “SSH to Server” button under the “Connect” list on the right side of the page. This will open the SSH Window in a new browser tab.
Enter “ec2-user” as the username. Select “Pem file” as the Authentication type. Upload the pem file in the “Pem file” field. Click Submit. You should now be connected to the EC2 instance via SSH. Run the computation command in.
Once you connected to the terminal, enter into the pipeline folder.
If you select the public pipeline, run the following command: sudo nextflow run main.nf -profile test_full,docker,batch
If you select the custom pipleline, run the following command: sudo nextflow run script7.nf -profile batch
Once computation flow is completed you can see the success information on the terminal.
Scroll to the top of the Terminal screen and click the “Terminate” button to end the session. Alternatively, type exit and hit enter in the terminal.
You can monitor the pipeline through “Monitor Pipeline” option.
You can view the outputs through “View Outputs” option.
You can de-provision the product through the “Terminate” option.
Through the Explore action you can see the shared files with 1-click. Note: If project storage is not mounted you can’t see the explore action in the product details page.
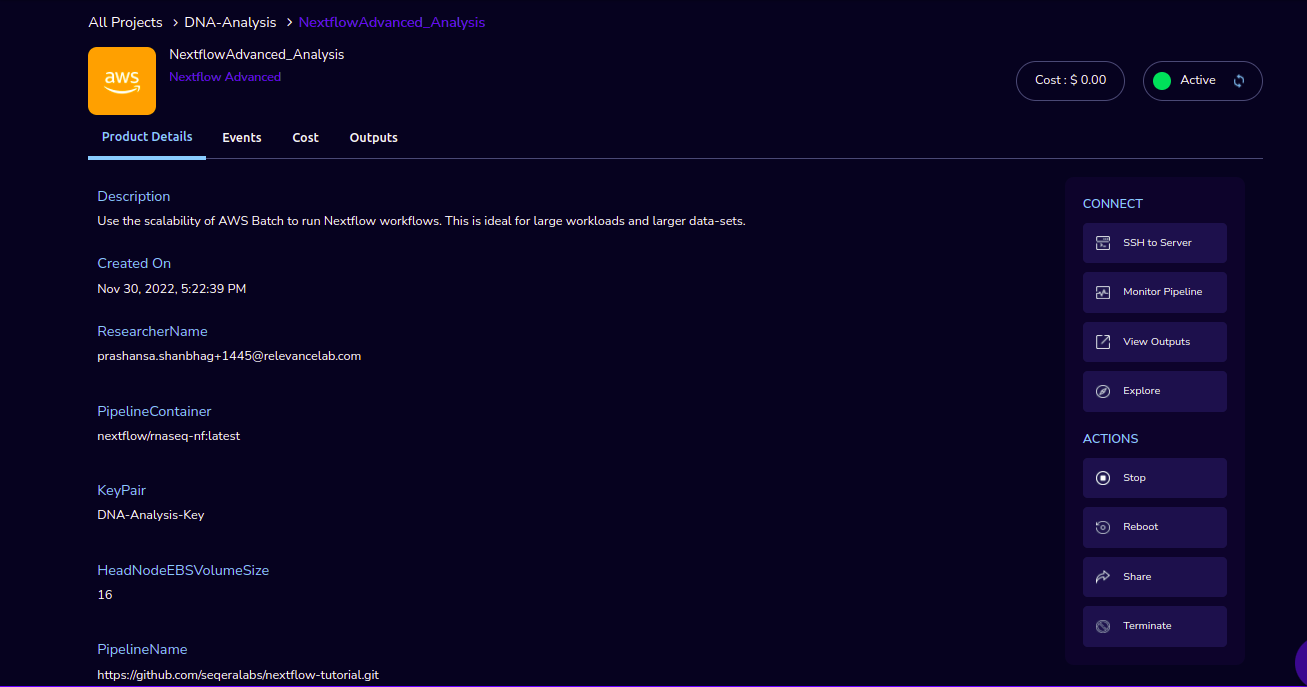
Other considerations
You can stop your instance using the “Stop” button in the product details page of your instance. The instance will incur lower costs when it is stopped than when it is running. You can also change the instance type when your instance is in a stopped state using the “Instance Type” button in the product details page of your instance.
You can share the product with all the members of the project using the “Share” button in the product details page of your product. If you share the product to project, you will have to share the PEM key file outside of Research Gateway.
Conversely, if the instance is stopped, use the “Start” button to get the instance “Running”.
You can attach a secondary EBS volume to your EC2 instance. First, create the EBS volume from the available products tab. While launching the EBS product, choose the same availability zone as your EC2 instance (find it in the Outputs tab). Once the EBS volume has been created, go to your EC2 Instance product details page and click the “Attach Volume” button and select the volume from the dropdown. Conversely, you can also detach it by clicking the “Detach Volume” button in the kebab menu on the Product Details tab.
Steps to follow to mount the secondary EBS volume to your EC2 instance:
- Create a file system on the newly created EBS volume. Here we selected the device name /dev/sdf at the time of attaching the volume
sudo mkfs -t xfs /dev/sdf
- Create a folder
sudo mkdir /data
- Mount the volume
sudo mount /dev/sdf /data
You can run the following command in the SSH terminal of your EC2 instance to determine if the EBS volume has been successfully mounted: lsblk
The volume will only be displayed in the list if it has been mounted.
Note
If you have already created the file system on the volume, then skip the command “sudo mkfs -t xfs /dev/sdf”.
For further details please refer to the AWS documentation